
跳表
redis 的有序集合是用跳跃表(skiplist)实现,这是一种比较神奇的数据结构
1. 简述
假如我们要用某种数据结构来维护一组有序的int型数据的集合,并且希望这个数据结构在插入、删除、查找等操作上能够尽可能着快速,那么,你会用什么样的数据结构呢?数组,还是链表
1. 数组
在查找方面,用数组存储的话,采用二分法可以在 O(logn) 的时间里找到指定的元素,不过数组在插入、删除这些操作中比较不友好,找到目标位置所需时间为 O(logn) ,进行插入和删除这个动作所需的时间复杂度为 O(n) ,因为都需要移动移动元素,所以最终所需要的时间复杂度为 O(n) 。
2. 链表
另外一种简单的方法应该就是用链表了,链表在插入、删除的支持上就相对友好,当我们找到目标位置之后,插入、删除元素所需的时间复杂度为 O(1) ,注意,我说的是找到目标位置之后,插入、删除的时间复杂度才为O(1)。
但链表在查找上就不友好了,不能像数组那样采用二分查找的方式,只能一个一个结点遍历,所以加上查找所需的时间,插入、删除所需的总的时间复杂度为O(n)。
3. 跳跃表
这时候,如果能够提升链表的查询效率,岂不是就完美了;
将链表每隔几个元素,提取出索引

这时候查找元素9,红色即为查找次数,通过这种方式可以加快查找速度

基于这种方法,对于具有 n 个元素的链表,我们可以采取 (logn + 1) 层指针路径的形式,就可以实现在 O(logn) 的时间复杂度内,查找到某个目标元素了,这种数据结构,我们也称之为跳跃表,跳跃表也可以算是链表的一种变形,只是它具有二分查找的功能。
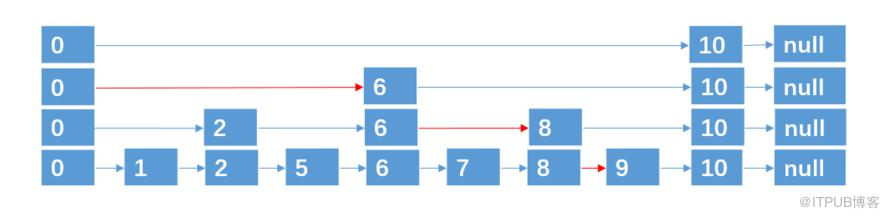
2. 跳表的插入删除
插入
上面例子中,9个结点,一共4层,可以说是理想的跳跃表了,不过随着对跳跃表进行插入/删除结点的操作,那么跳跃表结点数就会改变,意味着跳跃表的层数也会动态改变。
这里面临一个问题,就是新插入的结点应该跨越多少层?
实际上,跳表采取的策略是通过抛硬币来决定新插入结点跨越的层数:每次我们要插入一个结点的时候,就来抛硬币,如果抛出来的是正面,则继续抛,直到出现负面为止,统计这个过程中出现正面的次数,这个次数作为结点跨越的层数。
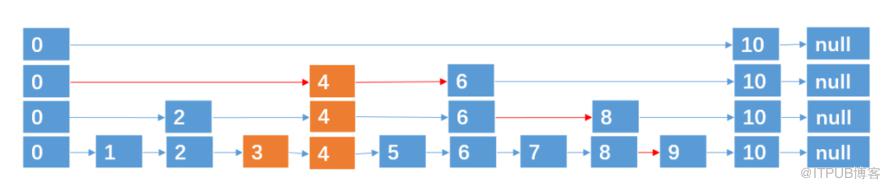
例如,我们要插入结点 3,4,通过抛硬币知道3,4跨越的层数分别为 0,2 (层数从0开始算),则插入的过程如下:
插入 3,跨越0层。
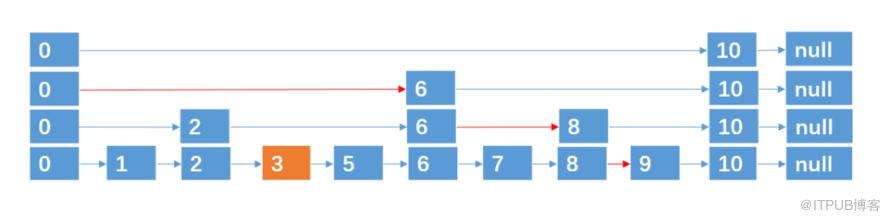
插入 4,跨越2层。
删除
解决了插入之后,我们来看看删除,删除就比较简单了,例如我们要删除4,那我们直接把4及其所跨越的层数删除就行了。
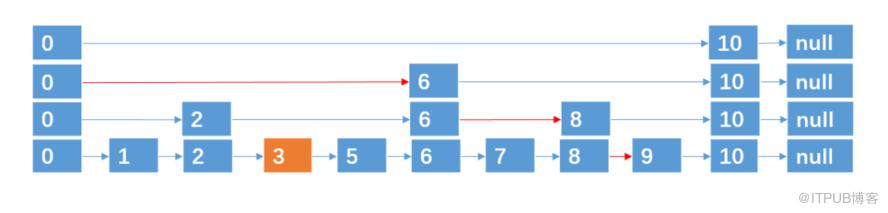
3. 性质
(1). 跳跃表的每一层都是一条有序的链表.
(2). 跳跃表的查找次数近似于层数,时间复杂度为O(logn),插入、删除也为 O(logn)。
(3). 最底层的链表包含所有元素。
(4). 跳跃表是一种随机化的数据结构(通过抛硬币来决定层数)。
(5). 跳跃表的空间复杂度为 O(n)。
4. 对比
跳跃表 vs 二叉查找树
二叉查找树是有可能出现一种极端的情况的,就是如果插入的数据刚好一直有序,那么所有节点会偏向某一边
跳跃表 vs 红黑树
红黑可以说是二叉查找树的一种变形,红黑在查找,插入,删除也是近似O(logn)的时间复杂度,但学过红黑树的都知道,红黑树比跳跃表复杂多了,反正我是被红黑树虐过。在选择一种数据结构时,有时候也是需要考虑学习成本的。
而且红黑树插入,删除结点时,是通过调整结构来保持红黑树的平衡,比起跳跃表直接通过一个随机数来决定跨越几层,在时间复杂度的花销上是要高于跳跃表的。
当然,红黑树并不是一定比跳跃表差,在有些场合红黑树会是更好的选择,所以选择一种数据结构,关键还得看场合。
参考以下文章,链接:http://blog.itpub.net/31561266/viewspace-2629925/,




